Symbolic Aggregate approXimation 또는 Symbolic ApproXimation을 줄여 SAX라 한다.
먼저 SAX에 대한 개괄적인 설명은 아래와 같다.
(느낌이 잘 오지 않는데, Creating SAX을 보면 이해가 될 것이다.)
SAX는 시계열(time series) data에 대해 time window로 나누고, 차원 축소를 하여 나타내는 하나의 방법이다.
클러스터링, 분류(classification), 인덱싱(index) 등의 고전적인 데이터 마이닝 기법에서, 잘 알려진 표현방법인 DWT(Discrete Wavelet Transform), DFT(Discrete Fourier Transform) 만큼 좋으면서, 저장 공간은 적게 필요로 하는 것이 바로 SAX 이다.
게다가, 생물정보학 또는 텍스트마이닝 분야에서 쓰이는 풍부한 자료 구조를 활용 가능할 뿐 아니라, 현재 데이터 마이닝 작업과 관련된 많은 문제에 대한 솔루션을 제공한다. (그렇다고 한다.)
Creating SAX
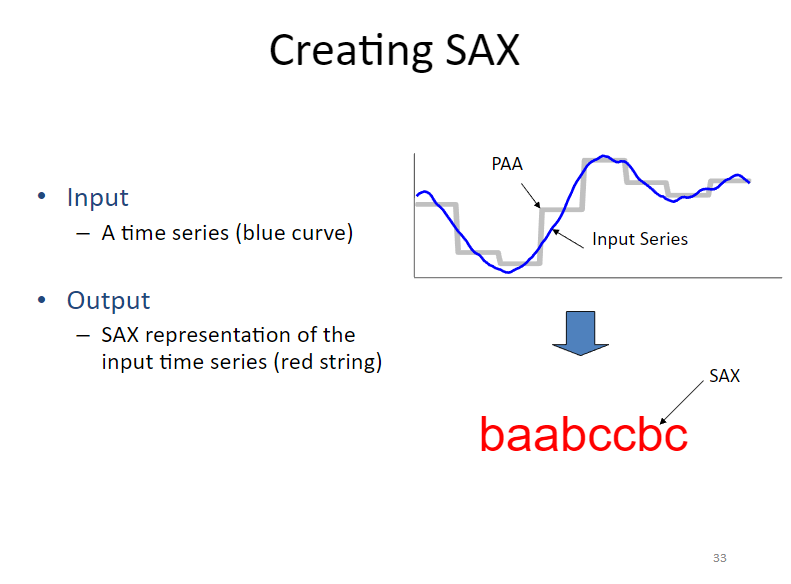
- Time series 형태의 Input이 들어오면, 계단형의 데이터 형태로 단순화한다. 이것을 PAA로 변환한다고 표현한다. (Piecewise Aggregate Approximation)
- 시간에 따른 곡선형 표현에서 계단형 모습을 바뀌게 된 것(PPA)을 텍스트 형태로 다시 기호화 한다. ex)aabbbccb 이런 형태로 표현된 것을 SAX라 한다.
PAA (Piecewise Aggregate Approximation)
Pros:계산이 매우 빠르다.
다른 접근방법들만큼 효과적이다. (경험적으로)
임의의 길이에 대한 질의도 처리 가능하다.
Can support any Minkowski metric
Supports non Euclidean measures
간단! 명료!
Cons:
그려보면 알겠지만, 썩 만족스럽지 못한 형태로 보인다.
Symbolic ApproXimation
- PAA처럼 시계열 데이터를 조각으로 구분하여 표현한다.- PAA에서는 표현한 측정치 대신 y축 또한 구간을 심볼로 표현한다. (텍스트 형태).
Symbol Mapping/SAX Computation.

PAA로 표현되는 y값에 대해 정규식을 통해 적절히 구간을 분류하여 구간별로 Symbol을 Mapping한다.
댓글 없음:
댓글 쓰기