2013년 1월, Hive의 속도 향상과 아파치 하둡에서의 데이터 효율성을 높이기 위해 ORC 파일을 만들었다. 높은 처리 속도와 파일 사이즈 크기를 줄이는 데에 목표를 둔 것이다.
ORC Specification
현재 ORC 파일은 2가지 릴리즈 버전이 있다.
- ORC v0 : Hive 0.11에서 릴리즈되었다.
- Hive 0.12 와 ORC 1.x로 릴리즈되었다.
현재는 ORC v2를 위한 작업 중에 있다.
지금까지 매우 간단한 ORC 소개를 해보았고,
이제 본격적으로(?) ORC v1에 대해서 보자.
ORC Specification v1
Motivation
Hive의 RCFile이 원래 수년간 하둡에서 테이블 데이터를 저장하는 표준 포맷이었으나, RCFile은 각 컬럼을 시멘틱 없이 binary blob으로써만 처리한다는 한계점이 있었다. 그래서 Hive 0.11과 함께 Optimaized Row Columnar (ORC) 파일이라는 새로운 파일 포맷을 추가했다.
ORC는 타입 정보를 함께 저장하며 이용했다. ORC는 타입 정보를 이용한 경량화된 압축 기법들을 사용했고 그럼으로써 드라마틱한 압축 효과를 볼 수 있었다. 여기서 말하는 경량화된 압축 기법이라 함은 사전 인코딩, 비트 패킹, 델타 인코딩, 연속 길이 인코딩(run length encoding)이었으며 추가적으로 일반적인 압축 방법(zlib, snappy) 또한 적용할 수 있다. 그러나 이런 저장공간 절약은 이점 중 하나에 불과하다.
ORC는 projection을 지원하여 어떤 컬럼을 선택하여 읽기를 요청하든 필요한 만큼만 읽어들여 원하는 컬럼값을 얻을 수 있다. 더 나아가 ORC file은 경량 인덱스(10,000 row 또는 전체 파일에 있는 컬럼에 대한 최소 최대값을 포함)를 포함하고 있다.
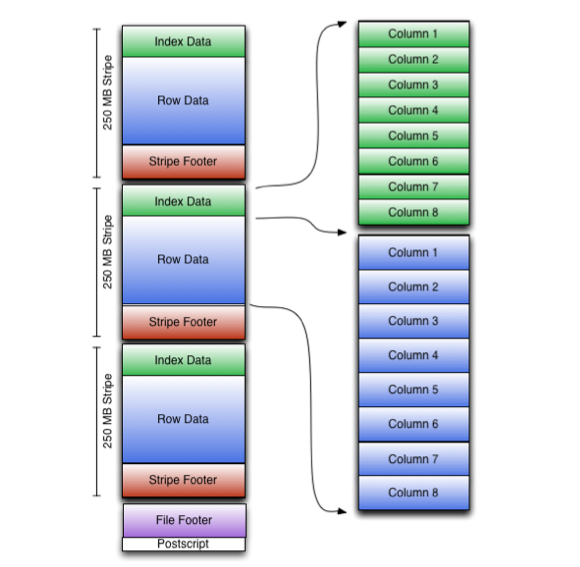
이후의 순서는 ORC 파일 내용을 읽기 위한 순서와 연결해서 생각하면 이해하기 쉽다.
1. File Tail : 파일을 뒤부터 읽어서 필요한 메타데이터를 사용
2. Compression : 압축별 헤더를 통해 skip 가능하도록
3. Stripes : 실제 데이터 부분
File Tail (파일의 끝부분)
HDFS는 파일 쓰기 이후에 데이터 변경을 지원하지 않으므로 ORC는 파일의 끝에 top level index를 저장했다.
먼저 알아야할 것이 ORC의 메타데이터들은 Protocol Buffer를 사용하여 저장된다. file tail은 아래와 같이 구성되어 있다. 오른쪽 정보는 해당 메타데이터를 표현하는 protobuf meesage type이다.
- 암호화된 stripe 통계 : list of ColumnarStripeStatistics
- stripe 통계 : Metadata
- footer : Footer
- postscript : PostScript
- psLen : byte
PostScript
ORC file에서 가장 처음 읽게 되는 정보라고 생각하면 된다. 나머지 파일의 어떤 부분을 어떻게 읽어야할지에 대한 기본 정보를 포함한다. 그러므로 Postscript는 압축되지 않는다.
- footerLength
- compression
- compressionBlockSize
- version
- metadataLength
- magic // the fixed string "ORC"
*version : 이 파일을 읽을 수 있는 Hive 최소 버전을 sequence로 나타낸다. ex) [0,12] : 0.12 버전 이상
Footer
파일의 바디에 대한 레이아웃 정보를 포함한다.
- headerLength
- contentLength
- (repeated) stripes // Stripe Information
- (repeated) types // Type Information
- (repeated) metadata // UserMetadataItem
- numberOfRows
- (repeated) statistics // ColumnStatistics
- rowIndexStride
- writer
- encryption
- stripeStatisticsLength
*Stripe Information : 각각의 stripe는 하나의 row가 나눠지는 일은 없도록 데이터를 포함시킨다. 그리고 stripe는 크게 3개의 섹션 indexes, data, stripe footer로 나눠진다.
*Type Information : ORC 파일 내 모든 row는 같은 스키마를 가져야한다. 그리고 tree 구조로 나타냄으로써 map, struct 같은 계층적인 타입으로 표현할 수 있다.
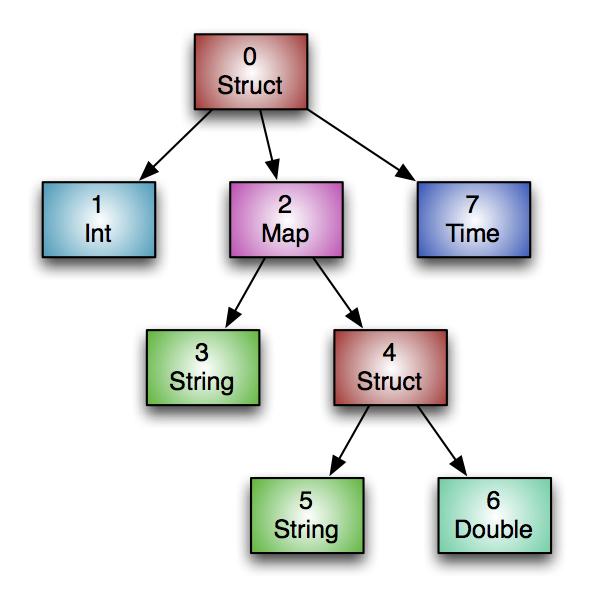
*User Metadata : 사용자가 임의로 key/value pair를 추가할 수 있다.
*Column Statistics : 파일내 모든 컬럼별 통계 정보를 저장하는데, writer가 타입별로 미리 정의된 유용한 정보를 기록한다. 대부분의 primitive 타입은 최소, 최대를 포함하고 숫자 형태는 sum까지 저장한다.
Metadata
- (repeated) stripeStats // StripeStatistics
* StripeStatistics는 ColumnStatistics Set
즉 metadata에는 stripe level에서의 컬럼별 통계 정보를 포함한다. 데이터 조건절에 대한 stripe별 평가 지표로 사용될 수 있다.
Compression
ORC file writer에 일반 압축 코덱(zlib or snappy)를 선택하면, Postscript를 제외한 모든 부분이 해당 코덱으로 압축된다.
그러나 ORC 요구사항 중엔 이런게 있다.
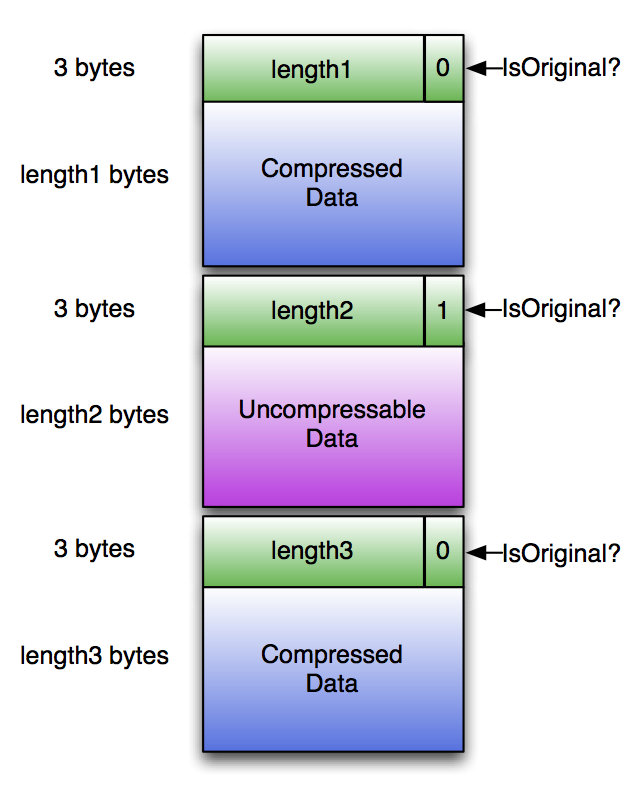
'reader는 전체 stream을 압축 해제하지 않고도 필요 없는 데이터(압축된)를 스킵할 수 있어야 한다'
그래서 ORC는 아래와 같이 청크별로 데이터를 압축하며 3 bytes의 헤더를 붙인다. 압축된 후가 더 크다면 원래 정보를 그대로 저장하며 isOriginal 비트에 체크한다.
compression chunk default size는 256K이긴 하나, writer에서 해당 값을 선택할 수도 있다. chunk가 커지면 압축률은 좋아지겠지만 더 많은 메모리를 사용할 것이다. 지정된 청크 사이즈는 Postscript에 기록되므로 그에 맞는 적절한 크기의 버퍼를 통해 데이터를 read할 수 있다. Reader는 압축된 청크를 해제하더라도 지정된 청크 사이즈보다는 커지지 않을 것이라는 걸 알고 있기 때문에.
Stripes
ORC 파일 바디는 stripe들로 구성되어 있다.
ORC 파일에서 각각의 컬럼은 여러개의 stream들을 통해 파일 내에 나란히 저장된다.
예1) integer column 같은 경우엔, PRESENT, DATA 라는 2개의 스트림으로 표현된다. PRESENT 는 데이터가 null이 아닌지를 표현하는 하나의 비트 표현이고, DATA는 null이 아닌 데이터를 기록한다. 모든 컬럼의 값이 null이 아니라면 PRESENT 스트림은 생략될 수 있다.
예2) binary data를 저장하기 위해서는 PRESENT, DATA, LENGTH를 사용한다. LENGTH 말 그대로 각 값의 크기(length)를 저장한다.
Stripe 구조는 아래와 같다.
- index streams
- data streams
- stripe footer
* index streams : row group index, bloom filter index
Stripe Footer
Stripe footer는 각 컬럼별 인코딩 정보와 stripe 내 stream에 대한 위치를 포함한 정보를 가지고 있다.
- (repeated) streams // Stream
- (repeated) columns // ColumnEncoding
- writerTimezone
- (repeated) encryption
*Stream : 각각의 스트림 정보를 설명하기 위해, 스트림별로 종류(kind), columm id, size in bytes를 저장한다.